【R】ありがたき{crosstable}パッケージで、集計や基礎分布の確認をラクにする
Introduction
高度*1な手法を使って効果検証や仮説探索を行う前に、まずどういうデータなのか確認するために2~3変数の関連をクロス表などで確認したい、ということは多い。
そういったときに、使えるのが最近開発された{crosstable}である。
"習うより慣れよ"なので、自分でコードを書きながら、主要な使い方のメモをここに残す
◆参考URL
引数の説明
公式ページの冒頭に
Crosstable is a package centered on a single function, crosstable, which easily computes descriptive statistics on datasets.
とあるように、基本的に{crosstable}パッケージはcrosstable()関数を理解すれば必要十分であるようになっている。
※一応Excelとの連携用の関数とかも充実しているっぽいが、ここでは触れない
ということで、主要な引数をみていく
- data: 第一引数, 対象のデータフレーム
- cols: 集計対象とする変数の指定ベクトル, NSEっぽく指定してもいいし(例 cols = c(var1, var2))、そのまま文字列で指定(例:cols=c("var2”, "var3"))してもいい。あとはtidyselectな感じでstart_with()とかcontains()とかも使える。詳しくはSelect variables • crosstableを参照のこと。
- by:グループ変数の指定。単一の変数でも、複数の変数でもよい(NSE指定 or 文字列指定)。基本的にはカテゴリ変数を指定する(byにnumeric変数を指定すると、相関が計算される)
- total:周辺度数をあらわすセルを追加するかどうかの指定。デフォルトは"none"(表示しない)で、"column"(列だけ追加),"row"(行だけ)、"both"(両方追加)のオプションがある
- percent_pattern:カテゴリ変数の場合に意味を持ってくる引数で、度数およびパーセントの表示形式を指定する{n}は度数,{p_col}, {p_row}はそれぞれ列/行%である。percent_pattern= "{n}({p_col})"のような形で、度数とパーセントの表示の仕方を指定する
- num_digits, percent_digits, 各セルの数値、パーセントに対する表示桁の指定
- labels:TRUE or FALSEを指定。TRUEのときはラベルを使う。ラベルはset_labels()を使って、mutate(new_col = set_labels(col, "This is Label."))のように設定する
- funs:数値変数に適用する関数をc(..)で指定する(何も指定しないとMin/Max, 中央値/IQR, 平均[標準偏差]が出力される)。
- funs_arg:funsに指定した関数の追加引数をlist形式で指定する。(例: crosstable(..., funs = c(quantile), funs_arg = list( probs= c(0.25 ,0.75)) )
- cor_method:byにnumeric変数を指定すると相関が計算されるが、相関の計算方法を指定("pearson" or "spearman" or "kendall")
- showNA:グループ変数がカテゴリである場合、NAの水準も表示するかどうか。"none"(デフォルト)、"ifany"、"always"のどれかを指定
だいたい上記が基本的によく使う引数っぽい。
よくある使い方の例
代表的な使い方についてコードをみていく
as_flextable()関数を使うことで, RStudioのViewerにHTML-likeな感じで表示できる、ので以下コードでもそうしている。
いつものように、{panelr}の賃金データを例につかう
data(WageData) dWage <- WageData %>% mutate( sex = if_else( fem == 1 , "female","male"), #性別 ed2 = if_else( ed > 12 , "high","low"), #学歴 occ2 = if_else( occ == 1 , "WC","BC")) #職業
数値変数の基本統計量
まず、基本的な使い方として、.funsに何も設定せずに、colsにnumericの変数を設定すると、最大値/最小値, 中央値/IQR、平均値/標準偏差, Nをグループ変数の値に応じて出力してくれる
dWage %>% crosstable( cols = c(wks , lwage , exp), by = c(ed2),label=F) %>% as_flextable(keep_id= F)

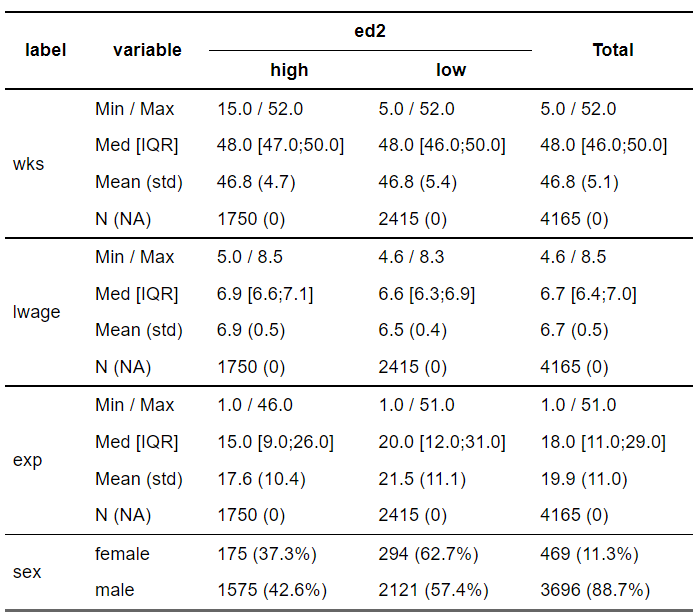
カテゴリ変数の要約&列和を表示する
カテゴリ変数に関しては、分布が示される。また、行の周辺度数をみたいので、total="row"をたしてみる。
dWage %>% crosstable( cols = c(wks , lwage , exp,sex), by = c(ed2), percent_digits = 1, label=F, total = "row") %>% as_flextable(keep_id= F)
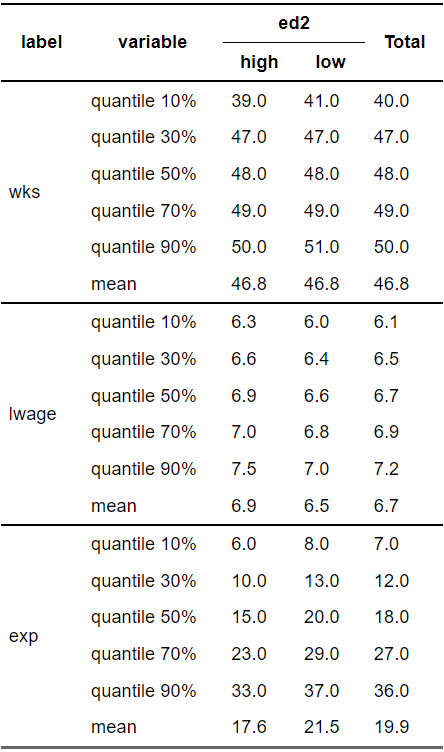
要約統計量の関数を自分で指定する
各変数ごとに確認したいのが分位点の場合、以下のようにfuns, funs_arg関数を使って指定する
下の例だと、平均も求めている
dWage %>% crosstable( cols = c(wks , lwage ,exp), by = c(ed2), label=F, funs = c(quantile,mean), funs_arg= list( probs = seq( 0.1 , 0.9 , by = 0.2)), total= "row") %>% as_flextable(keep_id= F)
グループ変数をふたつにする
個人的にこれが一番便利なんちゃうかな、という使い方
たとえば、学歴× 職業別に賃金,経験年数, 労働時間の分位点をみたいときなんかは以下のようにする
## 二変数で層別 dWage %>% crosstable( cols = c(wks , lwage , exp ), by = c( ed2 , occ2 ), total = "row", label=F, funs = c(quantile , mean), funs_arg= list( probs = seq( 0.1 , 0.9 , by = 0.2)) ) %>% as_flextable( header_show_n =T)

特殊な使い方
advancedな機能として、いくつか特定の用途に特化したオプションがあるので、そちらも見てくる
相関係数の表示
グループ変数を離散変数から連続量(教育年数)にかえて、相関関数を求める
dWage %>% crosstable( cols = c( wks , lwage, exp ), by = c(ed), label =F ,cor_method = "pearson", total="row" ) %>% as_flextable()

効果推定
effect=TRUEにすると、変数のclassに応じて、効果推定をしてくれる(byに指定されているのが二水準の変数ひとつの場合のみ)
詳しい指定の仕方とかは、Default arguments for calculating and displaying effects in crosstable() — crosstable_effect_args • crosstable(とそこから飛べる各関数のページ)を参照のこと
dWage %>% crosstable( cols = c(wks , lwage , exp), by = c(ed2), percent_digits = 1,funs = mean , label=F, total = "row" ,effect = T) %>% as_flextable()

連続量の場合は、内部で分布の正規性の判定がされて、正規分布だとみなされるならt検定が、そうでないのならbootstrap法での検定がなされるみたいだ。
おおまかな使いかたはわかった。
ひとまず初顔合わせのデータと仲良くなりたいときとかには使えるだろう
Enjoy!!
*1:というほど高度でもないことも多いが