最近よんで印象に残ったもの(2022年8-9月)
ここ1か月半くらいで読んだもののうち、記憶に残ったものについて少し備忘*1。
まとまって要約するというよりは、印象的なところを抜き書き。
読書はだいたいいつでもしているんだけど、ここのところ読んだ物は印象的なものが多かったので。
読んだそばから内容の7割くらい忘れる鳥頭なので、本当はもっとマメに記録とったほうがいいとは思うんですが、ものぐさなもんでね...
- 『語学の天才まで1億光年』(高野, 2022年)
- 『マスメディアとは何か:影響力の正体』(稲増, 2022年)
- 『パーソナリティのHファクター』(Lee and Ashton, 小塩監訳, 2012=2022年)
- 『旅する力:深夜特急ノート』(沢木:2008)
- 『セシルの女王』1-2巻(こざき亜衣:2022年~)
- 「人間の土地へ」(小松由佳, 2020年)
- つぎ消化したい積読
『語学の天才まで1億光年』(高野, 2022年)

- 中学か高校のときに学校の課題で『ワセダ三畳青春記』を読まされて衝撃を受けてからかれこれ10年以上私は高野秀行さんのファンなのだが、それを差し引いても今年読んだなかで文句なしのマイ・ベスト。
- アフリカ、アジア、南米など至るところに冒険し「辺境ライター」として生きてきた高野さんは、「語学のセンスがない」という自己認識がありつつも言語習得にのめり込み、多くのマイナー言語を含む数十の言語を「魔法の杖」として勉強してきた。そこでの発見を若い頃の面白エピソードとともにまとめた、いわば語学青春記である。
- 何を隠そう自分は本当に語学が苦手(特にリスニングが壊滅的で、若い頃英語の議事録を取らざるを得なくて死んだことがある)なので、高野さんの著作とはいえ楽しんで読めない可能性も少しはあるかもと思っていたのだけど、完全に杞憂だった(くらいすごい本)。食わず嫌いせず英語をちゃんと使えるようにせねば、と思えた。
- 短くまとめるつもりだったけど、あまりにも好きな本なのでどこかで時間をとって別の独立した感想記事にするべさ。
『マスメディアとは何か:影響力の正体』(稲増, 2022年)
")
- メディア効果論の気鋭の学者さん(お父さんも当該分野の有名な研究者というサラブレッドらしい)が出した新書。いやー、これも物凄い勉強になったし、門外漢だけど(門外漢だから、かもしれないけど)たいへん面白かった
- 「「メディアを疑うこと」を疑う視点」の重要性を説き、「マスメディア"への"ステレオタイプを鵜呑みにするな」と熱く主張する筆者は、たまに”マスメディア擁護派"と言われることもあるそうだが、一読した感じニュートラルで慎み深い姿勢を保っているようには感じられた。単純な悪玉論では理解も改善も進まない、というスタンスなのだろう。
- 昔、別の学者さんの本で「"メディアは信用できない"という情報や認識を、我々はまさにそのメディアを通して受け取っている」という旨のことが書いてあってハッとしたことがあったのだが、数年ぶりにそれを思い出した。
- SNSのアカウントを持っていれば目にしない日がないメディア批判(ex. 「マスゴミは~」「御用 or 左翼メディアが~」)の前提には、「メディアには強大な影響力がある」という我々の認識があるわけだが、まずその前提が本当に正しいかどうかについて、実証的な研究を参照しつつ勉強していきましょうという本である。
- メディア効果論の発展の歴史に沿って、原初的な強力効果論の紹介(第一章)→ いやいやメディアはいつでも効果を持つわけじゃなくて、それなりに条件が揃わないと人々には影響を与えられないよとする限定効果論(第二章)→ なぜメディアは過大評価されるのか、への説明(第三章)→ やっぱメディアの影響力って無視できないんじゃ?という「新しい強力効果論」(第四章)→インターネット時代のメディア効果論についての紹介(第五章)→メディアの未来への展望(第六章)、と非常にわかりやすい構成で、ひとつひとつの研究例がとても面白く勉強になった。ので、各章について簡単に要約&感想。
- 第一章:強力効果論とその実在性についての懐疑
- メディアが発信する情報が人々の意識・行動に対して強い規定力をもつとする見方である「強力効果論」に関して、その論拠として援用されることの多い二つの歴史的事象(①ナチスのプロパガンダ、②『宇宙戦争』事件←1930'sにウェルス原作のSFラジオドラマを聞いた人々が"実際に宇宙人が攻めてきた"と信じたとされる事件)が本当に強力効果論を支持するものとなりうるのか?という疑問を投げかけている。
- 「ナチスのプロバガンダが強力だった」というイメージを形成することは、ナチ・ヒトラー側にとっても、対抗勢力にとっても都合のよいものであり、(たしかにヒトラーの弁舌は巧みであったものの)事後的に構成・誇張された側面が強いことが指摘されている(pp10-11)
- 「宇宙戦争」事件がメディア研究において重視された歴史的経緯としては、世論研究者キャントリルがこの事件についてまとめた『火星への侵入』という学術書の存在が大きいのだが、"メディアが強力な効果をもつ"ことの根拠として援用されることの多いこの研究は、注意深く読めばむしろその後の「限定効果論」の嚆矢的研究であると著者は主張している。
- 「このように、キャントリルの研究は、どのような状況に置いて、どのような人々がパニックを引き起こすかを明らかにしようとした研究であり、マスメディアが「誰に対しても」「いつでも」強い影響力を持つことを示すような研究ではなかった」(p.24)
- はじめはニュースと聞いていた人々も、内在的/外在的チェックにより半数はニュースではなくドラマだと気づいたとのこと。また、「他人に言われてラジオをつけた」人はそうでない人よりも信じ込む割合が高く、学歴の高い人は信じ込む割合は低かったとのこと。"すごいことが起きてる、ラジオ聴けよ!”みたいな感じに言われてニュースを見始めた場合に批判的志向力が働かなくなるのは、ニュースというよりは他者の影響なのでは(そしてそれは限界効果論の中心的視座だ)とのこと。
- youtubeで検索すれば当時の音源があるよ!と書いてあったので、検索したらたしかに出てきた。いや、私の英語力じゃ字幕ないとアレなんですが(語学の天才まで100億光年だ..)、確かにサイレンとか叫び声とか、専門家への緊急インタビューとかあってめっちゃ手が込んでるのは分かる。たんなる朗読ではなくて迫真性がある。
- そもそもマスメディア強力効果論は、「「マスメディアは強い効果を持たない」という知見のインパクトを高めるための仮想的として、後の時代になって作られたものではないか」という見方もあるようだ(pp.26-7)。なるほどねぇ...ありそうな話ではある。
- 第二章:限界効果論について
- メディアの効果が限定的であること自体は、正直自明な現象である。では限界効果論がなぜ重要なのかというと、「マスメディアの効果が限定的なものにとどまる具体的なメカニズムを明らかにしたから」(p.29)とのこと。
- メディアの効果が弱まるメカニズムを表したp.30の図がとてもわかりやすい。無理やり文章に起こすと、以下のようになる
- 「集団・他者レベル」「個人レベル」という二つのレベルでメディアの効果は弱められる。個人レベルでの作用はさらに行動/認知過程の二つに識別される
- 「集団・他者レベル」では①集団内のオピニオンリーダーや他の構成員を媒介してメディアの情報が伝わるという「コミュニケーションの二段の流れ」によるフィルター、② ニュースに先んじて存在する準拠集団の基本的考え(先有傾向)からの逸脱しにくさ、③そもそも社会的文脈や地域・所属集団により触れられる情報が異なるという「デファクト選択性」、などがメディアの直接的作用に対する緩衝材になる
- 「個人レベル」では、①:個人がその選好や志向性に沿うように情報の取得を行うという「選択的接触」、が行動面でのフィルターとして、②-1:認知的不協和の低減、②-2:「動機付けられた推論」の存在、などが認知面でのフィルターとして作用する
- エリー調査(政治意識や投票をテーマとした多時点追跡の大規模調査で、7か月にわたり1940年に行われた)のデータを分析して書かれたラザーズフェルドの「ピープルズチョイス」が、各概念の説明に援用されているが、その知見が面白いのでいくつかメモ。
- そもそも分析した対象のなかで、支持政党が明確に変化したのは回答者全体の12%しかいなかったとのこと。そしてその6割には「交差圧力」(異なる政党への投票を促す要因が併存している状態)が働いていた。保守的な家庭で育ったけどリベラルな人が多数派の職場に勤めていたり、めちゃめちゃ厳格なカトリックの教育を義務教育段階で受けたけど、大学は革新・リベラルな雰囲気だぜ...みたいなパターンを想起すればいい(pp.37-8)
- 選挙への関心が高い層は、プロパガンダに接触しやすいのだが、そもそも支持政党から発せられたものに接触が偏っているために、基本的にメディア接触は先有傾向を強化する。「マスメディアを通じて発信された情報がもたらす効果の中心は、投票先を変更させる「改変効果」ではなく、もともと持っている態度を強める、あるいは曖昧であった投票先を明確化する「補強効果」である」(p.41)とのこと
- 各集団における「オピニオンリーダー」に着目して、「コミュニケーションの二段の流れ」仮説を提出したのが『ピープルズ・チョイス』の貢献のひとつ。追試的な調査・研究も含め、オピニオンリーダーは多くのメディアや情報に接している傾向がある。
- 「コミュニケーションの二段の流れ」モデルは、かの有名なロジャースのイノベーション普及モデルにも大きく影響を与えているとのこと(アーリーアダプターがX%いて...っていうアレ)。はえーっ!確かに同じ構造ではあるな
- メディアの効果が限定的であることの論拠としての「選択的接触」は、ひとつのメカニズムとしては認知的不協和の低減が、もうひとつには「動機付けられた推論」が想定されている。「動機付けられた推論」は社会心理学者クンダが提起した概念であり、ここでは「正確性」と「方向性」の軸が紹介されている。「正確性」に動機づけられている情報探索ばかりではなく、"自分の意見に沿ったこういう情報が欲しい"という「方向性」の動機による情報探索行動も多くある旨。
- ただ、「選択的接触」というのは個人の認知過程が情報摂取の偏りの主因とする見方ではあるが、そもそも置かれている環境・地域・集団などの文脈によって入ってくる情報が違うんじゃないの?という「デファクト選択性」による偏りも大きいことがわかってきたため、一時そういった問題関心は下火になったとのこと。ただ、インターネットが普及したことにより選択的接触の問題をまた考える必要が出てきた(pp.74-5)
- 第三章:「第三者効果」と「敵対的メディア認知」についての説明
- 前章で、メディアの効果は限定的であるということ、そしてそれはなぜかということを説明したが、それでもなお人々が「メディアは人々を強烈に支配している」と思ってしまうのはどういう仕組みになっているのか、というのを説明した章。
- 「第三者効果」は「自分自身に対するメディアの影響力と比べて他者への影響力を過大視する」心理的傾向、「敵対的メディア認知」は「マスメディアの報道を自身の立場とは逆の方向に偏っているとみなす」という心理的傾向のことである。いってしまえばシンプルだが、多くの追試がされ、再現性が高い知見らしい。
- 「第三者効果」の話は本当に面白くて、これはありていにいってしまえば『「自分だけは賢いからメディアに影響受けないけど、周りはバカだからメディアに簡単に影響される」と、みんなが思っている』という状態として現代社会のメディアの影響力認知をとらえる見方なのだけど、人間の志向のニュートラルポジションがわりと"自分に甘く他人に厳しい"ものなんだな、と突き付けられるような気分になった。
- 敵対的メディア認知の話も、言われてみればそうだろうなって感じなんだけど、具体的な研究例やデータが出てくるとなかなかインパクトがある。同じニュースをみても、A党支持者は「B党に都合いいように偏向している」とみなし、B党支持者は「A党におもねった内容である」とみなしてしまうのである。いやー、これもすごいわかるなぁ。ある情報に関して「敵か味方か」みたいな観点から吟味するとき、人は減点法に走りやすいということなんだろうな。"俺らに不利"な情報ばっかりみつけてしまうという。
- 第四章:「新しい強力効果論」
- この本ではここまで、大まかに言えば、①メディアに文脈普遍的な強力な力はなくて、効果が発揮される状況は限定的だ、② そんな限定されたメディアを僕らは過大評価しちゃうんだ、っていうのを解説してきたけど、それをもう一回ひっくり返す章。"マスメディアには、意見を直接変えさせる力はないが、そうでない方法で人々の考えを大きく規定している"という研究例が多く紹介される
- 政治学者コーエンの言葉「ニュースは人々の考え(what the public think)に影響を与えることには失敗しているかもしれないが、人々が何について考えるか(what the public thinks about)に影響を与えることには驚くほど成功している(p.129)」が、この"新しい強力効果論"のポイントを端的にあらわした言葉として引用されている。なかなか重いし、SNSが浸透したいまでもかなり当てはまる点があるように思う。しかも読み進めていくと、「実際には、議題設定という過程を経ることで、マスメディアは間接的に人々の考えにも影響を与えていると言えるかもしれない」(p.133)という知見も紹介されている。
- 議題設定理論(メディアでの報道量が、人々の各テーマやトピックに関する重要性の認識に影響する)自体はまぁそうだろうな、という感じなのだが、メディアが短期スパンで人々の認識や行動選択に影響を具体的なメカニズムとしての「プライミング」と「フレーミング」、長期スパンでの影響について扱った「培養理論」についての具体的な研究例が非常に興味深かった
- プライミングとは、ある争点報道について接触したのちに、評価や行動選択にその争点が強く影響するようなメカニズムのこと(例:外交についてのニュースを聞いたあとだと政治家をより外交政策に重きをおいて評価する)。アイエンガー&キンダーの嚆矢的な研究では、いろいろなトピックで、実際に政治家の評価において事前に視聴した動画のプライミング効果が確認されている(p.155)
- フレーミングとは、ある情報をどういう枠組み(frame)で扱うかによって、受け手に及ぼす影響が変わってくる効果のこと。論理的に等価な情報が異なった形式で提示されるものを「等価フレーミング」、内容は広い意味で一緒だが強調点が異なる枠組みが提示されるものを「強調フレーミング」という(p.158)。
- 強調フレーミングの具体例の話がかなり面白いと同時に怖さを感じさせる話で、同じ社会問題を扱った報道でもテーマ型(より抽象化した、マクロな視点で問題を扱う)のフレームによる報道より、エピソード型(特定の人物・出来事にスポットをあてる)フレームの報道のほうが個人に帰責しやすい認識につながる、というアイエンガーの研究が紹介されていた(pp.158-161)。いやこれめっちゃわかる。マクロ統計とか雇用問題としての「貧困」に対して否定的な人でも、ひとりひとりの困窮した人々に対して”どう思う?"って突き付けられると割と自己責任論的に振る舞うというか。これは別に日本的な現象ではないんですね。勉強になったなぁ。
- 培養理論では、長期的・継続的なメディア(ここでは主にTVが想定されている)接触が、人々の社会への認識にどういう変化をもたらすかが扱われている。面白かったのは、①TVの視聴時間が長いと、「より世界は暴力的である」と認識するようになる(暴力に遭う確率を高く見積もったり、他人への信頼が低下する)が、学歴が高いとその効果は低くなる*2(pp.170-172)、②TVに長時間接触しているひとびとは属性差を超えて、似通って社会認識をもつという「主流形成」現象(pp.172-174)、③主流形成とは逆に、属性や所属集団による差がTV視聴によって広がる「共鳴」現象(pp.185-186)、あたり。必ずしも一様な効果が得られるわけじゃないってのが逆に興味深いですね。
- この章を(メモをとるために)こうやって読み返してふと思い出したのは、クリストファー・ノーランの『インセプション』だった。
- あの映画では、アイディアを"盗む"んじゃなくて"植え付ける"のがインセプションだと序盤に説明がある。しかし、あれはアイディアやメッセージそのものを植え付けようとしているというよりは、フレーミングやプライミングをやっているのでは、とこの章を読んだあとだと思えてくる。
- ケン・ワタナベ扮する大企業のトップに依頼されて、ライバル企業の跡取り息子に巨大企業グループの解体をさせるのが奴らの目的なんだけど、やり方としては夢のなかで「財閥を解体しろ!」ってメッセージを直接伝えるわけじゃなくて、その行為にポジティブなイメージ(親との和解や、自分自身での決断など)を想起させるようなフレーミングをおこなっているわけですな。また、企業グループを解体するか否かの判断を、「父親との和解」というトピックに引き付けて判断させるという意味ではプライミングである。
- 第5~6章はそこまで目新しい話があったわけではないので詳細は割愛。フィルターバブルやパーソナライゼーションとその帰結などの話に関しては、昨年末に読んだサンプター(『サッカーマティクス』の人)の『アルゴリズムはどれほど人を支配しているのか?』のほうも合わせて読むといいなと思った。意外とメディアは人の意見を変えられない、という最終的な含意に関しても一致している。

『パーソナリティのHファクター』(Lee and Ashton, 小塩監訳, 2012=2022年)

- あんまり心理学系の本は読まないんだけど、以前著書を読んだとき面白かった学者の方が監訳者だったので手に取った。
- 「監訳者あとがき」で、その監訳者が「本書の最初にエピソードとして示されたように、学生時代に見いだしたアイデアが世界中で注目されていくというのは、研究者にとっても憧れの姿なのではないだろうか」(p.182)と述べているように、著者のふたりは学生時代に国際調査のデータの分析から、当時(そして今も)パーソナリティ心理研究において大きな影響をもつ「ビッグ・ファイブ」モデルではとらえきれない6つめの次元をみつけた。それがタイトルにもなっている「Hファクター」である。
- 「H」はHonesty(正直さ)-Humility(謙虚さ)の略であり、これと元のBig5に含まれる5因子を合わせた6つの因子を包含するモデルを、各因子の頭文字をとって「HEXACO」と名付けている。それぞれ、以下の略である
- H:Honesty/Humility
- E:Emotionality(情動性, 元のBig5では「神経症傾向」にあたるもの)。共感性が高かったりいわゆる「繊細」さをもつほど高い
- X:eXtraversion(外向性)。社交的だったり明るい場合に高く、より内向的で引っ込み思案であると低い
- A:Agreeableness(協調性):寛大さや優しさ、平和を好む人では高く、強情で喧嘩っ早いひとだと低い
- C:Conscientiousness(誠実性):規律や勤勉性の高い人間で高く、怠惰や無責任なひとだと低い
- O:Openness to experice(経験への開放性):知的好奇心や発想力の高い人間で高く、前例を踏襲したり閉鎖的な人間で低い
- 2012年、つまり10年前に原著は出版されているが、訳者あとがきによると「残念ながら、HEXACOがビッグファイブに置き換わるような研究の展開は今のところない状況」らしいが、HEXACOとビッグファイブがともに言及・引用する、併存状況ではあるそうだ。
- 「H」はHonesty(正直さ)-Humility(謙虚さ)の略であり、これと元のBig5に含まれる5因子を合わせた6つの因子を包含するモデルを、各因子の頭文字をとって「HEXACO」と名付けている。それぞれ、以下の略である
- パーソナリティの心理学的研究を紹介・援用する本によくあるパターンとして、「○○な人は△△な傾向がある」という類型論の紹介が続く...という展開がある。この本も後半はそういう構成になっている。これはこの本のクオリティが云々の話ではなくて完全に個人の趣味の問題なのだけど、そのパターン「だけ」ではあんまり面白くないと思ってしまう派なので、ちょっと後半は流し読みという感じになった。どっちかというと、そこに環境や社会構造の話が絡んできて、問いがミクロ-マクロの重層化の形になってないと面白く思えないんだよな。
- とはいいつつも、いくつかの面白いポイントも少なくない箇所あったので、それを書き留めておく。
- O(経験への開放性)因子、C(誠実性)因子、X(外向性)といった三つの因子の高さがその時代や環境における適応に対して果たす力が、「その社会がどういう社会か」によって変わる、という話(pp.23-25)はかなり面白かった。O/C/X因子が高いことにはメリットとデメリットがあるのだけれど、時代や環境あるいはその社会の発展段階によって、そのメリットとデメリットのバランスが変わっていく、という話だ。
- 以前読んだJane Jacobsの『市場の倫理 統治の倫理』を想起して、色々考えが刺激される話ではあった。『市場の倫理 統治の倫理』は(クソ長い本なので強引にまとめると)「世の中の"道徳"や"美徳"と呼ばれるものは、大まかに二つの群に分けることができて、その一方は市場経済の発展に寄与し、他方は統治・権力機構の十全な作動に寄与する」ということが主張されている本なのだけど、O因子やX因子が高いことは「市場の倫理」が重視される社会でより生存に対して有利に働く、ということなのだろう。
")
- 出生順とパーソナリティの関連性についての実証研究があるらしく、面白いなと思った(Sulloway, 1996, "Born to Rebel", URL)。出生順が遅いほど反抗的なパーソナリティとなるとのこと。この傾向が、どの国や社会階層でも共通するのか、それとも違いがありうるのか、というのも気になるところではある。
- 米国の歴代の大統領のパーソナリティを、彼らに詳しい伝記作家やジャーナリスト、学者への他者評定から測定する、という研究があるらしく、興味深かった(pp.58-60)。これ日本じゃ絶対やれないだろうなぁ*4。
- 社会的・心理的・身体的な特徴が類似したものどうしが結婚や友人関係において結びつく同類結合について、HEXACOの各因子は重要な役割を果たすのかどうかを検討した部分も面白かった(pp.102-104)
- HEXACOのうち、同類結合にかかわるのはH因子とO因子のみ、とのこと。すなわち、正直さや謙虚さの度合いが似ている人や、知的好奇心の旺盛さが似ているような人は友人になりやすい、とのこと。もちろんここでいわれているのは平均的な統計的関連性で、絶対的な説明則ではないから、自分や周りに思いを馳せればその反例はいくらでもみつかるんだけど、割と納得感はあった。違っているからこそ仲良くやれる、みたいなのも一方ではあるんだけどもね。
- 個人的には政治意識、特に右翼権威主義(RWA, right-wing authoritarianism)および社会的支配志向性(SDO, Social dominance orientation)に焦点を当てた7章がかなり面白かった
- RWAは(その国の)伝統的規範を重視し、そこからの逸脱への排撃を支持するような志向で、SDOは(その国・社会の)支配的階級におもねるような、「分相応」からの逸脱を嫌う志向性を指す。
- RWAとO因子は負の相関がある(これはまぁそうだろうなという感じ、新しい発想や経験を嫌う人のほうが保守的で伝統による支配を好むだろう)んだけど、その関連は年齢を重ねるにつれて強くなるという話(pp.114-115)が面白かった。たぶん因果の方向性としてはO→RWAが想定されている(「O因子の低い人々は社会において保守的な立場のほうにしだいに引き寄せられており、O因子の高い人々はそのような立場から遠ざかっていく」,p.115)のだが、まぁ逆もあるんだろうな。
- この事象(O因子⇔RWAの関連が年齢につれて高まる)への説明仮説として、「年齢が高まるにつれて、親の態度(や政治的・宗教的)の影響が弱くなり、遺伝的な影響が強くなる」ことが挙げられているのが興味深い(p.116)。O因子がある程度遺伝的に決定されていて、RWA決定における相対的重要性が年齢につれて高まっていく(親の影響は普通弱まっていくから)ので、ということである。
- SDOとH因子には負の相関があり、正直さや謙虚さや道徳性を重視する人々は、社会的不平等に反対する傾向があるとのこと(pp.120-121)。これはもっとツッコむと、機会の平等と結果の平等のどっちを扱うのかでも違いが出てくるのではないかと感じた(SDOの測定尺度にはどっちも混ざっている気がする)
『旅する力:深夜特急ノート』(沢木:2008)
")
- ノンフィクションライターの先駆け的存在である沢木耕太郎が「深夜特急」シリーズの締めとして出したエッセイ。
- 近年、若い人が個人経営の小規模な本屋を出す流れがあるようで、東京の各地にそういう本屋ができている。自分の家の近くにも若い店長がやっているその類の喫茶スペースつき書店があり、そこでたまたま目についたので購入。
- 本を買うことも、人気や新着の本の情報を得ることも、もっぱらオンライン経由になりつつある世の中で、私も例外ではなくほとんどAmazonで買ってしまっている。でもリアル書店にはやはりリアル書店だからこそのよさがあるとは常々思っていて、個人的には大型書店で圧倒的な数・種類の本に囲まれることがその魅力の最たるものだったんだけど、最近こういう個人書店も良いな、という風に思うようになった。
- 狭いスペースに、店主の琴線に触れたセレクトされた本が並んでいるのは、「どんな本もありそう」な大型書店とは違う良さがある。友人の家に遊びに行ったときに、本棚を見ながら彼らのこれまで・これからの関心や好奇心の軌跡に思いを馳せるのって結構楽しいんだけど、その楽しさに似ている。
- 「深夜特急」シリーズ自体を読んだことがなかった(藤井聡太竜王の小学生時代の愛読書らしい。どんな小学生やねん)ので、てっきり勘違いしていたのだが、沢木氏の旅は鉄道・電車(や船や飛行機)をなるべく使わずに「デリーからロンドンまで乗り合いバスで行くこと」が基本コンセプト(実際にはさらに手前の香港から出発)で、実際にそれをほぼ遵守した旅であったとのこと。
- 「パキスタンのバスはすべてクレイジー・エクスプレスと言ってよい」(p.168)のエピソードが印象的。ボロボロの車両でギュウギュウ詰め、ドアや窓も閉まらなかったりするのにわけわかんほどスピードを出し、挙句の果てにバス同士でレースを始める、とのこと。
- この本以外でも、アジアやアフリカなどの(当時の)途上国のバスの運転のワイルドさ(婉曲表現)を描写する本はたくさんある。ちょっとずれているけど自分が印象的に覚えているのは、高野秀行×清水克行『世界の辺境とハードボイルド戦国時代』で出てきた話で、一昔前は日本中世の研究者はインドに旅行に行くと各地での警察の取締まり(ドライバーがワイロを渡して通してもらう)を見て中世の「関所」についてのアイディアを思いつく、という話だった。ウソやろって思ったけど偉いな歴史学者で数人そういう人がいるらしい。
- 当時の一般的なルートはヨーロッパに飛行機に行って西からアジアに入っていく、というルートだったらしいが、沢木氏があえて西進するルートにした理由として彼がはじめての海外旅行で韓国に降り立った時の原体験が挙げられている
- 「ここからパラシュートで降下し、地上に舞い降り、西に向かってどこまでも歩いていけばパリに行くことができるのだな。もちろん、その間には北朝鮮があり、中国があって通過できないだろうが、原理的には歩いてヨーロッパに行けるのだな、と。そのときの心のときめきはいつまでも体の中に残っていた」(p.103)
- 特にメモとかとってないんだけど今年読んでかなり面白かった本のひとつに、江戸末期~明治期に当時の日本の辺境(蝦夷地、八丈島、台湾)で探索したり紀行文を残したりした何人かの話をまとめた宮本常一「辺境を歩いた人々」があるんだけど、当然ながら当時電車や飛行機は日本にないから彼らは物凄い距離を歩いていったわけで、それを読みながら「原理的には歩いて東京から鹿児島まで行けるんだよな」とか考えてたのを思い出した。当時は遠国への旅をするのも数か月・数年がかりだったし、ある種それまでの生活基盤を捨てる覚悟を持つ人々が旅人だったわけだ。
- 沢木氏が「深夜特急」の旅をしていたのは26歳の頃で、出版後に影響された読者が26歳前後に長期海外旅行に出てしまう事例が続出していたと回顧している。
- 手前味噌的にそこから沢木氏は26歳くらいが海外放浪する「旅の適齢期」であるとの持論を展開する。なんか強引すぎる気もしたが、齢を重ね、経験を積みすぎてからの旅は感動や印象はどうしても少なくなるから、「経済的に余裕ができたら..」などと思わずにある程度若い頃に思い切って放浪せよ、というのは理解できる気がする。
- 「あの当時の私には、未経験という財産付きの若さがあったということなのだろう。もちろん経験は大きな財産だが、未経験もとても重要な財産なのだ。本来、未経験は負の要素だが、旅においては大きな財産になり得る。なぜなら、未経験ということ、経験していないということは、新しいことに遭遇して興奮し、感動できるということであるからだ」(p.296)。「未経験も重要な財産」ってのは、なるほどなぁと思った。確かになぁ。
- これも世代的に知らなかったんだけど、90年代後半に「深夜特急」シリーズは”ドキュメンタリードラマ"という形で映像化されており、その主演を大沢たかおがやっていた。ということで、巻末には沢木×大沢対談が載っている。大沢さんにとっても転機となる作品だったらしく、それまで出演作の中心だったトレンディードラマ*5に体質的に戻れなくなったらしい。面白いなぁ。
- 「以前から、そこで演技をしているんだかどうかわからないような芝居をしたいと思っていたんですね。それを「深夜特急」の中で存分に実験できる毎日を過ごしたあとでトレンディードラマの世界に帰ってくると、ハイそこで振り向いて「愛してる」と言ってください、みたいな芝居にどうしても入っていけないんですよ。そこから監督やスタッフの人たちと溝ができるようになってしまって」(p.370-371)
『セシルの女王』1-2巻(こざき亜衣:2022年~)
 (ビッグコミックス)")
- 「あさひなぐ」の作者の最新作。舞台は16世紀の英国で、主人公はエリザベス1世の側近として長きにわたり活躍した初代バーリー男爵ウィリアム・セシル。
- 「あさひなぐ」は近年のスポ根モノのなかでも最高級に好きな作品であるが、全然違う題材に挑むチャレンジ精神がすごい。そしてとても面白い。
- イギリスというと、有名な女王の長期在位期間が歴史上何回かあった国でもあり(読んでいるときには予想だにしていなかったが、歴代最長であったエリザベス2世が逝去されてまた今は男性国王の時代となった)、日本に比べればそこまで男性君主へのこだわりはないようなイメージがあった。しかし、この1-2巻はヘンリー8世の妃達の、壮絶な「男子を生むこと」へのこだわりが物語の中心として描かれており、英国でも女性君主はあくまでもアノマリー扱いだったのか、と。
- 尾篭な話でアレだけども、セシルが時の枢機顧問官トマス・クロムウェル(ピューリタン革命で活躍するオリヴァー=クロムウェルは彼の姉妹の子孫)への接触を図るシーンで、「糞壺の交換をしにきました」と偽って彼の部屋に入ろうとするのが、当たり前だけどなるほどと思った。下水道の整備なんて歴史的には本当に最近のことなんだよな。
- 一応世界史選択だったけど受験後一週間でインプットした知識の95%が忘却された私でも覚えている"ブラッディ"メアリが、まだ少女ながら後に爆発するであろう苛烈さを孕んだとても良いキャラとして登場しており(エリザベスはまだ2巻終了時点では幼児)、彼女がいかにして「血まみれ」になっていくのかが楽しみである。
「人間の土地へ」(小松由佳, 2020年)
")
- 若干24歳でK2登頂を果たした著者が、その後シリアのパルミラのある家族と深く関わるようになった中でシリア内戦が勃発し、多くの困難に直面しながらもその家族の末っ子と国際結婚し、その後色々な苦労がありながらも2人で日本の生活地盤を築いていくまでのノンフィクション。件の本屋で棚に並んでいるのを見つけて、「語学の天才~」の高野さんが発売当初に激賞していたのを思い出して購入。これも今年読んだなかで3本の指に入る面白さだった。
- 上で書いた「旅の力」でもいくつか腐敗したアジア各国の警察の話が出てくるが、シリアの警察がワイロありきで動いているという話が興味深かった
- 「『シリアでは賄賂が社会の潤滑油。賄賂を渡すという事は相手に敬意を払うということだ』。ある友人の言葉だ。善いか悪いかではなく、それが国の行政に対するしきたりだった」(p.140)
- 「抜け道」という認識ですらなく、賄賂を渡すのが正道になっている、と。わりと最後のほうで「シリアには税金が存在していることを知らないまま生きているシリア人がたくさんいる」と書いてあって衝撃を受けたのだけど、公権力に対する市民の金銭的負担とその引き換えとしての職務への監視、みたいな意識は決してグローバルに通底したものではない、ということか。
- 内戦開始後、裏業者にカネを積んだり軍から命がけ脱走したり、といった壮絶な思いをしてシリアから亡命した大勢のうち、かなりの部分が難民キャンプでの生活に生きる意味を見出せなくて、結局虐殺や武力衝突が起きているシリアに自ら戻る選択をした、というのが印象に残った。それまでの人生を過ごしてきた縁や関係性から遊離した宙ぶらりんな状態となるほうが、命の危険にさらされることよりも辛いことなのだ。
- 難民へのサポートや受け入れ体制みたいなものを考えるとき、まず経済的・物質的な支援にばかり頭がいってしまうんだけど、本当に彼らが慣れない地で前に進めるようにするためには、彼らが故郷で大事に培ってきた周りの人間との関係性やそこで育まれた尊厳みたいなものを取り戻す/新たに作り上げることが可能な環境を用意する必要があるのだと感じた。
- 著者の夫となるラドワンさんも、戦時中に徴兵され、市民運動の弾圧などに政府軍としての出動を余儀なくされることに心を痛めてヨルダンに命がけで軍を抜けて脱出したものの、またシリアに戻って反政府勢力に参加した。だがそこで結局政府軍と同じような現実があることに絶望して再亡命し、著者と結婚して来日するものの、日本での生活が安定するのにかなり時間を要した..という激動の人生を歩んだ方であった。
- 来日後にラドワンさんはいくつもの職を転々とし、精神的にどんどん疲弊していってしまうのだが、結局彼を救ったのは、①同じようなムスリム系の先人が作った会社(賃金は最低賃金を下回るものの、シリア人の「ゆとりを重視し、あくせく働かない」ペースが許される)で働き始めたこと、②日本にもモスクがあることを知り、そこに通い始めて似たような経験をもつ人たちとの関わりを持つようになったこと、だったということ。
- シリアで悪質な盗難の被害に何回か遭った筆者は、本書前半でその理由として「日本人の数日の稼ぎが、シリア人の一か月ぶんの稼ぎに相当するという格差・不平等感」を挙げている。だが本の終盤でいざ「日本で働くシリア人」に(本人は望んだものではないけれど)なる機会を得た彼女の夫が本当に必要としたのが、稼ぎの良さではなく彼がパルミラで培ってきたような生活のリズムの回復を支える組織や関係性であった、というのが示唆的であった。
- この本の後半は一種の「国際結婚モノ」としても読めるんだけども、結婚当初に著者が、シリア人と結婚・離婚したカナダ生まれの女性から授かったアドバイスの内容が性生活に関するかなり具体的なもので、まぁ実際にとても切実なんだろうけどインパクトがあった。ムスリムの男性/女性観といわゆる先進諸国の男女平等観みたいなものの狭間で、ちょうどいい塩梅の折り合いを見つけるまでの著者の苦闘もなるほどと思った。
- 「お互いの価値観を完全に理解できなくても、そのわからないことをリスペクトして、共にいられること」こそが大事なのだという彼女の辿り着いたスタンスは、別に国際交流に限らず、同じ文化圏や家族内のコミュニケーションであっても求められることなのだろう。
- 中立だけど傍観・諦観せず、色々な対立する立場の声を聴く、という筆者のスタンスが本全体を通してよく文章に現れていて、かくありたいと思わされる本であった。

")
")
")
{stm}パッケージ用に、日本語ドキュメントのベクトル⇒BoW表現のリスト&単語ベクトル、の変換をする
別記事を書いていて、トピック単体で切り出したほうがいいなと思ったので。
その記事はたぶん近日あげる*1
Introduction
{stm}パッケージ(構造的トピックモデルを推定するためのRパッケージ, CRANのURL)を使うための自分用備忘の記事を、vignetteとか読みつつ書いていた。
で、当たり前だけど元々は英語圏のパッケージなので、基本的に日本語特有の処理のことはvignetteその他には書いていない。
あと私は普段自然言語処理とか関係ない人生を送っているので、そこらへんの土地勘がない。
なので、調べながら備忘メモを残す。
解くべき問題
stmのメイン関数stm()を推定するとき、第一引数documentsと、第二引数vocabを指定する必要がある
documentsは、文書数だけ要素数があるリストで、各要素は
- 一行目に単語の種類を表すindex
- 二行目に単語の登場回数
を格納した2×(登場した単語の種類)の大きさの行列である(下の画像参照)

で、vocabはこの一行目の各indexと対応するのが何かを表す単語である

これを、日本語テキストが対象のときにどうするか、という話。
Data
大昔につくった、2020年J1リーグの監督の試合後会見コメントのデータを使う。取得時点での終了試合なので正確には2020年シーズンのうち、2020/10/14までの会見データである

How to transform
色々調べながら変換にいたるまでの悪戦苦闘を記録しておく
RMeCabでターム-文書行列を得る
docDF()関数を使うと、ターム-文書行列が得られる(引数type=1にする必要がある*2)
以下では、
- minFreq = 5を使って、トータル5回以上出ている語だけに絞る
- posで、名詞・動詞・形容詞だけ
retTerm2 <- docDF(dfCmnt20, "Comment" , type = 1, pos = c("形容詞","動詞","名詞"), minFreq = 5) tail( retTerm2,3)

出力は↑のように、行が各単語、列が単語/品詞/i番目の文書における登場回数..という形のデータフレームになっている。
なんとなく、うまく変形すれば求める形になりそうな予感だ。
BoW表現を得る
stm::stm()にかけられるような表現をここから得るような関数を以下のようにかく
処理内容としては、
- docDF()の戻り値にIndexを付与して、各RowXX列(文書を表す)が0でない=その単語が登場してない行を抜いて行列化→置換して、stm()の第一引数にかけられるようなリストにしてる
- TERMから単語ベクトルを取得して、stm()のvocab引数に渡すベクトルとする
- 一応品詞情報もデータフレームとして取得しておく($dfVocab)
をやってる
docDF_toBoW <- function( doc_df ){ ## args; # doc_df: RMeCab::docDF( .. , type = 1, ...)の戻り値 doc_df <- doc_df %>% mutate( Index = row_number()) # # 語彙ベクトル(と品詞情報)を得る dfVocab <- doc_df %>% select( TERM , POS1 , POS2 , Index) vecVocab <- dfVocab$TERM # stm::stm()の引数documentsに指定できるような形に変換する doc_n <- doc_df %>% select(starts_with( "Row")) %>% ncol #文書数の取得 doc_info <- list() #空のリストとして初期化 for( i in 1:doc_n){ # cat( i, ",") row_tgt <- paste0( "Row", i) row_q <- rlang::parse_expr(row_tgt) tgt_df <- doc_df[, c("Index",row_tgt )] term_cnt <- tgt_df %>% filter( !!(row_q) > 0 ) doc_bow <- term_cnt %>% as.matrix() %>% t() doc_info[[i]] <- doc_bow } #for return( list(BoW = doc_info, Vocab = vecVocab, dfVocab = dfVocab )) } #function #使用例:形容詞・動詞・名詞かつ登場回数が5回以上に品詞を限定 retTerm2 <- docDF(dfCmnt20, "Comment" , type = 1, pos = c("形容詞","動詞","名詞"), minFreq = 5) retBoW2 <- docDF_toBoW(retTerm2) # ver2: さらに種類を絞る jclb20 <- c( "東京","札幌","川崎","大阪","名古屋","鹿島", "柏","横浜","大分","浦和","鳥栖","神戸","清水","仙台","湘南") retTerm2_v2 <- retTerm2 %>% filter( !(POS2 %in% c("数", "代名詞","接尾","非自立")) ) %>% filter( !(TERM %in% jclb20 )) retBoW2_v2 <- docDF_toBoW(retTerm2_v2)
監督コーパスに対して適用してみた結果は以下の通り

それっぽい形に頻度行列を要素としたリストができてる。

サッカーっぽい単語ベクトルができてる。
おまけ:ちゃんとstm::stm()が適用できるかのチェック
推定まで
お前ほんとにそれ{stm}の前準備になってんのかよ!!というお叱りもあるかもしれない(ごもっともだ)
ので、実際にやってみる。
{stm}は文書属性情報を共変量として用いることができるのがメリットなので、
- 得点数
- 失点数
- 得点期待値(Football LAB算出)
- ボール支配率
を紐づけてみよう
j1_meta20 <- left_join(dfCmnt20 , j1_stat %>% select( Date , Club , Goal_For , Goal_Against , Expected_Goal,Possession = Possesion), by = c("Club","Date") )
登場回数が多すぎる単語と、少なすぎる単語を除外して前準備する
prep_JBoW20_v2 <- prepDocuments( retBoW2_v2$BoW , vocab = retBoW2_v2$Vocab, meta = j1_meta20 , lower.thresh = 10 , upper.thresh = 350)
トピック数を10に設定し(10特に意味のない適当な数字。本当はsearchK()関数などを使って、精査したほうがよい)、STMを走らせる。
jSTM_k10<- stm::stm( documents = prep_JBoW20_v2$documents, K = 10, data = prep_JBoW20_v2$meta , vocab = prep_JBoW20_v2$vocab , prevalence = ~ Goal_For + Goal_Against + Expected_Goal + Possession)
推定後の確認
推定された各トピックの代表的wordは、以下のようになっている
jSTM_k10 %>% plot.STM( type="labels")

代表的なトピックについて観察していくと、
- 2020年はコロナ禍最初のシーズンで、数か月の中断を挟んだこともあり、かなり詰め込まれた修正日程が組まれ、かなりハードスケジュールであった。「連戦」というワードを含むTopic6/8はそういったピッチ外の環境に言及したものである
- 「サポーター」「感謝」「思い」などが入っていることもあり、Topic6のほうがより周りへのメッセージという意味合いが強く、Topic8は「コンディション」「チーム」といった単語を含み、よりチームへの影響に重点が置かれている
- Topic9は、相手の最終ラインの枚数への言及(「バック」)や、「質」「市」「前線」といったワードを含むことから、戦術的な振り返りを行うトピックである
- stm::findThougts()は各ドキュメントに対して算出される、トピックの割当事後確率をもとに、各トピックと関連の高い文書を上位から取り出せる関数である(詳しくは下のコード参照)。たとえばTopic9の割合が高い会見コメントとしてtop3に入るものとして、下平監督(当時横浜FC)の以下のようなコメントがあげられる
前半の最初は本当に良い入りをして、相手も面を食らったような感じで自分たちのペースでやりたいことができていた。ただ、時間帯によっては疲れてきて、やりたいことができない時間もある。守備は確かにマンツーマンでやったけど、そこはリスクを負ってやったので、そこで良い形で奪えれば自分たちに点が転がってくるし、入れ替えられれば相手のビッグチャンスになる。そういうリスクを負ってやっているので、球際やフィニッシュのところを含めて勝ち切れるようになっていったら、もっと面白いかなと思います。失点の形は前節もそうですけど、クロスからやられている。3バックでやっているぶん、5枚にハッキリなっていれば完全にはね返せるけど、3バックに任せることによって、3バックの大外でいつもやられていることが多い。ウイングバックをやる選手の守備力はもっと上げないといけない。かなりハードなタスクを攻守で課しているので、そこで戻り切れなくなっているという戦術的な理由も当然あると思うけど、そこは逆に言えば、3バックの選手にははね返せる力をつけてほしいし、選手の能力をもっと伸ばしていきたい。ハイラインが特徴的なチームなので、そこの背後はFC東京と鹿島のゲームを参考にだいぶ狙っていました。ただ、守備力のところで鹿島やFC東京はボランチのところでボールを取れて、そこからのカウンターが効果的にできていた。なかなかウチは中盤でボールを奪えなかった。プランはあったにせよ、それを遂行する力が足りなかったと思いました
↓代表的文書をとりだすためのRコード
# topic 9のhighly associated documentsを上位4個とりだす fT9 <- findThoughts( jSTM_k10 , texts = dfCmnt20$Comment , n = 4 , topics = 9) #トピック9を4個 fT9$docs[[1]]
- Topic2は分かりやすい反省の弁で、最も関連の強い文書としては2020年、横浜FMに0-4で敗戦を喫したときの片野坂監督(当時大分)の会見があげられている(URL:【記者会見】片野坂知宏監督「点を取りたい意識が強くなりすぎバラバラになってしまった」 | 大分トリニータ公式サイト)
ということで、
日本語ドキュメントからBoW形式変換→前処理して、{stm}パッケージで分析するさいの段取りが分かった
Enjoy!!
JMP分解について:備忘ノート
Introduction
人間の(いや私だけかもしれないけど)の何が哀しいって、それなりにそのときは時間をかけて理解したつもりになったことでも、そのあと思い出す機会がないと数年したら跡形もなく忘れていたりすることである。
この記事もそれを防ぐ系のアレ。
経済学とかでよく見る(といっても因果推論の議論がすすんだ最近は流石にすたれてるけど)Blinder-Oaxacaのもうちょっと高度なversionでJuhn et al. (1991)*1で提案されたJMP分解ってのがあって、仕事関連で調べものしていたら5年以上ぶりに再会したんだけど、あれ?君誰だっけってなったので再学習。
参考URLなど
- Yun(2007) ※たぶん正規に論文化したものは2009年の[https://onlinelibrary.wiley.com/doi/epdf/10.1111/j.1467-9485.2009.00475.x
- JMPを使ってたりする例としてのLee and Wie(2017), ※working paper versionはこっちから見られる
JMP分解の概要
上のYun(2007)を読みながら適当にメモをとる。
前段としてのBO分解
有名すぎるBlinder-Oaxaca分解は、ある集団Aと別の集団B(あるいはある時代と別の時代だったりもする)のOutcomeの平均値差をOLSの結果を使って、以下のように分解する。

ここで、第一項はcharacteristic effectsとよばれるもので、各独立変数の(平均の)分布差によるアウトカムの差異をあらわす。
第二項はcoefficients effectsというもので、群間の各独立変数の回帰係数の差異に由来する、アウトカムの差異をあらわす。
第三項は、普段は明示して示されない(けどJMP法との比較上あえて式に残している)誤差の平均値差で、誤差はゼロ平均だからその差もゼロになる。
これは、群Aと群Bの双方でOLSをかけてるから(回帰モデルの性質上)ある意味当たり前のことである。
JMP分解:①効果の同質性を仮定ver
JMP分解のひとつめのBO分解との大きな違いは、各群ごとにOLSを推定「しない」という点にある。
BO分解でいうところの、coefficients effectの存在を想定しない、ということである
手順は以下の通り。
- まず、群AだけでOLSを実行して係数推定値を得る。係数
が得られる。
- この係数と群Bにおける変数Xを組み合わせることで、以下のような群Bの残差
が得られる

- ここで、群AvsB間の平均値差は、以下のようになる
ここで、でる。
この分解の第一項はpredicted gap, 第二項はresidual gapと呼ばれる。
residual gapはBO分解になかったものであり、観測されないスキルの分布の差異を反映するとJMP的には捉えられる。
ただ、このJMP法は、coefficients effectは無視しており、residual gapが係数の違いとは独立に決定されることを仮定していることに、注意しなければならない
逆に言えば、JMP分解の立場は、BO分解におけるcoefficients effectが群間での異なる"biased" estimatesによるものだとしている、とも換言できる(p.6のはじめ)
※ただ、Oaxacaさんもこのmisspecificationの可能性については自分で言及しているらしい。
JMP分解:② 群間での効果の異質性を考慮するver
それでもアウトプットとして効果の差が観たかったり、coeffficients effectsが把捉したい場合は以下のように拡張する。

ここで、となっているし、
は各群の残差の標準偏差である。
残差についてはpooledなデータに対してのモデルの推定値(から得る)
第一項はcharacteric effects, 第二項はcoefficients effectsで、第三項は残差(unoberved skills)の平均値差による差、第四項は残差の分散の差による差であるといえる。
なるほどー。
Conclusion
残差を利用した手法は単純に読んでて面白い
趣味でやってるサッカーのデータの分析にも使えそうな話だと思った。
ゴール期待値とそこからの乖離ってまんまモデルの予測と乖離の話だもんな
Enjoy!
「佐々木、イン、マイマイン」(2020年, 内山拓也監督)
基本的に劇場で観たもの以外(DVDや各配信サービスが初見の場合)、自分はほとんど一度みた映画を短期間で何度も見返すことはないんだけど、これは2週間弱で3.5回くらいみてしまった。
自分が100回くらい見返してる邦画ってひとつしかないんだけど、この作品も加わるかもしれないなってくらいなんというか色々感じる映画だった。
そういう、何度も思わず折に触れて見返しちゃう映画って、若い頃の感性で摂取したからそういう刺さり方をするんであって、もう良くも悪くも老兵と化した今、もうそういう映画には出会わないのかなって思ってたんだけど、アラサーだからこそ刺さった映画なのかもしれない。主人公とだいたい同年代(自分のほうがちょい上)だし。
色んな創作コンテンツはわりとその場で消費して完結してしまうタイプだけど、あまりにも刺さりすぎたので、順不同で感じたことを書き留めていく。
誰が読むわけでもないんだけど、これから何回も観ることになるのならば、観たばかりの今の時点で感じたことや心のフックにひっかかったことを、アットランダムに書き残しておくことで、そこからの感じ方の変化も含めてこれから長く深く楽しめると思うので。
別の100回くらい見返してる映画は、初見時(15歳くらい)の感想をどこにも書き留めてなくて、「はじめはどう感じてたんだっけ」ってのを知る術がない*1ので、こっちは残しておこうと思った次第。
と、いうことで、「考察」とか「分析」じゃなくて、ただただ感じたことを適当に。印象的なシーン多すぎて、選べないし。
- 佐々木「悠二、やりたいことやれよ。.....お前は大丈夫だから。堂々としてろ」..は(色んな他の人の感想を観てても)この映画のひとつのハイライトシーンだと思われるし、自分もこの映画を思い出すときにずっと脳裏に浮かぶのだろう。
- 父子家庭でしかも父にネグレクトされている佐々木が、そこまで深刻じゃないにしても祖母と二人暮らしで色々事情があると思われる悠二に「お前は大丈夫」ということの意味を、映画を観終わってからも考えさせられる。
- 「お前「は」大丈夫だから」、っていうのは「俺は大丈夫じゃない」ってことの言い換えだっていう指摘を別の場所でみて、それは確かにそうだなとも思ったんだけど、それ以上の願いが込められてるようにも思えた。わかってくれてありがとう、その分がんばれって
- 自分自身もそれなりに問題がないとはいえない家庭や父親*2のもとで育ったので、自分はまだ大丈夫な悠二の側なのか、それとも佐々木の側に近いのか、みたいなことをぼーっと考え込んでしまった。大人だし、色んな現状や選択を他人や環境のせいにはしたくないし、自分のことは自分で責任もって、大丈夫にしていくしかないんだけど。
- 冒頭の多田との再会シーンもとても印象的で、観てくうちに印象がかわっていくんだろうと思えた
- 初見時は、悠二との関係性がまだ観てる側にはわからないこともあって、なんか多田の物言いの刺々しさや偽悪的な振舞いにいろいろ心をざわめかされる
- でも「XXXとか汚い言葉を俺の前で使うな」って直接言っても関係が壊れない友は、まぁ貴重だよなって二回目からは思える。意外とこういう人のほうがたくましく真面目にやってたりするんだよなー....
- 「あのとき佐々木コールしてたら..」って悔やむモードに入りかける悠二に即座に「悠二....佐々木、あのまんま、良い顔してたな。だれも、何も、悪くないんだよ」って言えるのは強い。自分だったら、まっすぐ「いやそうじゃなくてさ」..みたいな感じで馬鹿真面目に返しちゃうと思うんだけど、いったん「良い顔してたな」って挟んで、気持ちを立て直す"間"をつくってあげられるのもやさしさだなーと。
- 終わりが近づいている男女の関係性の描き方みたいなものも、なんかほんとうますぎて、色んな観てる人が色々思いだして「うぐぅぁぁぁ....」「あぁ....」みたいな声にならない声を出したんじゃなかろうか
- 悠二みたいに「彼女と別れても同棲を続ける」ほどロックな経験*3は流石にないんだけど、(半)同棲していてかなり長く生活時間を共有しているなかで、一方あるいは両方の気持ちが終わりに近づいていることはお互いに伝わっている...みたいな状況のなんともいえなさ、気持ちが相対的に残っているほうの整理の付け方の難しさ、みたいなのは本当に(恐ろしく)よく描かれていたと感じた。
- 物語中盤でユキ(同棲中の元カノ)が酔って帰ってきて、なしくずしにそうなりそうだったけど必死な悠二がふと顔をあげたらユキが寝ちゃったシーン。悠二が気持ちを落ち着かせるためにたばこを吸おうとするんだけど、マッチが切れてて、しょうがなくキッチンのガスコンロでつける..しかもそこで画が引きになってサマにならないトランクス姿で佇んでる悠二が映されるのがなんか哀しくも笑ってしまった。未練が捨てきれない男って端から見ればこんなもんですよね...でも本人はそれなりに何か真剣に起きないかと願っているんですけどね...と。煮え切らなさこそが人生だ......煮え切らなさこそが人生だけど、冷静に考えたら次いった方がいい(けど難しい)。
- なんというかあの2人の部屋の荒み切ってはないけど、華やかではなくちょっと澱んだ感じとかも絶妙で、この映画の美術さんにもシネマドリでそこらへん語って欲しい感があった
- 最後に悠二が別れの決意を伝えるシーンで、ユキは「私もずるい女だったよ(大意)」みたいなことを言ってて、まぁ実際そういう感じはそこまでの各シーンからは看取できるので、ここで「女性はしたたかや~」みたいな一般論に持っていくこともできるんだけど、それよりは単純に生活時間を多く共有した人と別れるのって大変なんだよなぁ、という種の印象を持った。コンコルド・エフェクトじゃないけど、単純に今あるものを手放すのって人間できないじゃないですか。変化って怖いじゃないですか。
- 自分は映像論・映画論みたいなものやその枠組みを勉強しているわけじゃないので、ほんと素人感想でしかないんだけど、光(と影)のつかい方がうまいと感じた。
- 何より、悠二が木村家で赤ちゃんを抱かせてもらったときに涙が止まらなくなったシーン
- 自分も2-3年前に親友の生まれたばかりの赤ちゃんを抱かせてもらったときに気が付いたら涙が出てきちゃったことがあって、悠二が他人に思えなかった。
- 「悠二がなぜ涙を流していたのか」については、明示的に作中で語られてないからこそ本当にいろんな解釈があって(タマフル(今はアトロクか)の映画評とか、他のブログの解釈とかも読んだ)、解釈の可能性自体が開かれているのがこの映画の良いところだよな、と思った
- 藤原季節さん(悠二役)と細川岳さん(佐々木役)が本当に素晴らしい俳優だった
- 佐々木コールができなかったあのシーン、細川さんの演技が絶妙で、どうしようもないつらさを明るさで隠そうとするけど、それでも慟哭してしまいたくなるような悲しみに耐えきれなくなっていく佐々木の表情や声色をこれ以上なく形で伝えていた。あれがあるからこそ、そのあと俯いたまま涙を流す悠二が映されたときに心を揺さぶられるわけで。
- 作品全体を通して、同性ながらに「藤原さんの顔の綺麗さがすごい」と感動しながら観ていた。学ラン来たらちゃんと高校生に見えるし。
- 積極的に何かを伝えようとするわけでもなくて、基本的には繊細でさまざま鬱屈を抱えながらもがいている、悠二という人物が(物語中盤で舞台の監督に言われる)「不器用でできなくて何がだめなの?」とそれでも前を向こうと歩き始めるようになるまでの様を演じるのに、本当にこの藤原さんの配役は最高だったと思う。彼の出る作品はこれからも観てみたい
- なんか人生めっちゃ順調やわー、みたいな人よりかは、(深刻度に濃淡はあっても)難しい状況に置かれている人こそ、滋味深く感じられる作品なのかな、と思う。少なくとも自分にはそう映った。
- この映画を観た人ひとりひとりに対して、各々の人生で出会ってきた佐々木的存在(あるいは佐々木そのものに)に、「もう大丈夫だし、堂々としてるよ」と言えるようになるためにもう一度頑張ろう、と思わせてくれる作品なのかな、とも。
- 40になったとき、50になったとき、あるいは人生の終局に差し掛かったときにこの作品を観て何を感じるんだろうか。
Enjoy!
*1:なんか部活の練習試合ですごい落ち込むことがあって、友達に泣き言言いながら帰って、それでも気が晴れなくってなんとなく家からでてふらふら自転車で何も考えずうろうろしてて、ふらっと入ったレンタルDVD屋に立ち寄って借りて見た..みたいなどうでもいいことばかりおぼえてる
*2:何も悪びれず息子の骨をへし折ったりとか。「骨折り損のくたびれ儲け」という言葉を自分以上に身に染みて感じている人間はそこまでいないのではないか
*3:いや、自分が勝手にそう思ってるだけで今の若人はそれが普通なのだろうか。老兵にはわかりません
*4:なつかしすぎる。64 Switch Onlineでくるって言われてずっと楽しみにしているのにそれから一年が経ちそうなんだが...
【データ分析】Jリーグでトランジション・ゲームを制するのはどのようなクラブか
データからみるJリーグシリーズふたたび
はじめに:トランジションゲームになると得するのはどういうクラブか
このまえtwitterをながめていたら、以下のようなtweetが目に入った
J1今季18チームの、攻撃+被攻撃回数(≒トランジション回数)と平均走行距離を川崎の対戦成績と比べてみた。見事にトランジションが多くたくさん走るチームに勝ち点を落としている。#川崎フロンターレ pic.twitter.com/GBKXIB7B57
— フロアカ (@FrontaleShu) 2022年5月26日
フロンターレのゲーム内容については、今シーズン1試合=自分が応援するクラブとの試合しか観戦していないので、何も語れない。
ただ、データだけ見ると(ACLとの並行日程による過密っぷりの影響を差し引いても)少なくとも去年よりは苦戦している印象もあって、ゴール期待値が低下している(参考tweet)ほかに、下図の通り2021年とくらべてハイプレスについての試行回数と成功率が低下している、ということも確認されていた。

で、私個人の関心は、川崎フロンターレ単体の内実よりも、もうちょっと広く一般的な問いにあって、
「本当にハイトランジションな展開が得意/不得意なクラブは存在するのか、だとしたらそれはなぜか」
というのがそれである。
というわけで今回は、2020-22の2年半ぶんのデータを使って、ハイ/ロートランジションなゲームを制するために必要な強みは何かを探っていく。
分析の方法と仮説
※テクニカルな説明なので、結論だけ知りたい人はとばしてよい
データ&変数
Jリーグ公式サイト、Football LABおよびSofaScoreにおいて公開されている各指標のデータを利用する
対象とするのは、2020年の全306試合、2021年の全380試合、そして2022年の5/25開催までの134試合のデータを利用する。
変数としては、以下を利用する。
トランジション指標は、上述のフロアカさんのやりかた(自軍攻撃回数+敵軍攻撃回数)でもよいのだけれど、
昔自分がトランジション指標を用いた分析したときはmin(自軍攻撃回数, 敵軍攻撃回数)にした*1ので、今回もそうする*2。
分析に用いる指標(変数)は、以下の通りである。
分析アプローチ
サッカーってのは、つまるところ「相手より一点でも多く点をとること」が勝利条件となるスポーツだから、
- 得点を多くとること
- 失点を少なく抑えること
のふたつが必要になる。
そこで、「Jリーグでトランジション・ゲームを制するのはどのようなクラブか」という一番大きな問いは、以下のより具体的な形に変換された問いに対して答えを見つけ出していくことで解いたことにする。
ここで「ハイトランジションなゲームで.. ..より重要になってくる」という表現がなされていることが、この問いの要諦である。
すなわち、ロートランジションなゲームと、ハイトランジションなゲームでは、各チームがもつ強みがどれだけ有効かが変わりうる、という分析上の想定をおいている、ということだ。
ハイトランジションなゲームで、そうでないゲームのときよりもひときわ得点/失点に強い効果をもつ特徴変数がいくつか見出されるとすれば、そういった特徴を多く兼ね備えたクラブは「ハイトランジションなゲームに強い」と言えるだろう。
したがって、さしあたってのデータ分析の目的は、
「得点/失点(outcome)への効果が、その試合のトランジションの度合い(mediator)によって変容するような、予測変数(predictor)を見つけ出す」
ことだと表現できる。やや統計っぽいことばでいいかえれば、得点/失点への影響においてトランジションと「交互作用」をもつ変数を特定する、ということだ。
分析手法としては「因果木」という方法を使っているが、詳細はとてもとてもむずかしい話になるので割愛する。
※一年前に天候によって効果が変動する変数を検討した記事↓と同じものを使っている。
今回の場合に引き付けてわかりやすく説明していえば、「その試合のトランジションの激しさ」によって「得点or失点」に与える効果を変化させる変数が何か、を探すのに最適な機械学習の手法を使っている、とだけ理解できればそれでよい。
分析
というわけで、分析をすすめる。
本チャンの分析をするまえに、トランジション指標の基本分布や主要変数との関連をみる
プレ分析:ハイトランジション志向のチームの優位性の確認
まず一番はじめに、2020-22の累積データからトランジション指標の分布を描いてみる
平均は113.6回で、中央値は114、10%分位点が99回、90%分位点は129回である

(なんか右のほうの外れ値で1試合とんでもないのがあるが、これを確認したら今年3/18の横浜FMvs鳥栖戦(0-0)で、確かに走行距離もスプリントもかなり高い数値になっていた。
ここ数年のマリノスはハイプレス・ハイライン・ハイトランジションの疾風怒濤サッカーでおなじみだし、鳥栖も若くモダンで攻撃的なチームなので、納得感はある)
※蛇足だが、2020/21の各年でもっともロートランジションな展開のゲームをしていたのはセレッソ/清水で、これはミゲル・アンヘル・ロティーナが監督をしていたという共通項がある。彼が就任した神戸も、これから大きく平均トランジションが下がっていく可能性はある。
次に、2020/21/22各年度の各クラブの平均トランジションと平均勝ち点を順にプロットしていく。

図から確認できるここ3シーズンの動き*4として、
- 全体傾向としてトランジションが激しくなっている(=グラフの右に寄っていっている)
- 2020に比べて2021→2022のほうが、トランジションと平均勝ち点とが関連するようになってきている(=各点の分布が右肩上がりになっていっている)
が確認できる。
簡便な数値指標からもこの傾向を確認するために、各クラブの平均トランジションと、平均勝ち点/平均得点/平均失点の相関を年度ごとにみてみる。

なかなか興味深い結果が得られた。以下のことが読みとれる
この節では、非常に簡易な分析ではあるものの、ここ3年のJリーグのおおまかな傾向として
「ハイトランジション志向なチームの比較優位性が(得点面を中心に)高まっており、リーグ全体としてもハイトランジション化の傾向がみられる」
ということが確認できた。
さて、これをふまえてメインの分析では、ハイトランジションなゲームでより多くの果実を得るための条件となっている変数を探索する。
本分析:トランジション・ゲームを制するために必要な条件
ハイトランジションなクラブが得点増を通じて勝ち点を稼いできている近年の傾向も把握したところで、この記事のメインの問いである「Jリーグでトランジション・ゲームを制するのはどのようなクラブか」に直接迫っていく。
ハイトランジションなゲームほど効果が高まる変数を、見つけるのである。
まず、得点から見ていこう。
ハイ・トランジションであることによる利得の分水嶺となる変数を、因果木によって索出した結果の、主要部分が以下である。

この図は、各ボックスの上部に表示されている数値が、その集団における「ハイトランジションであることの得点数への効果」であり、ボックス下部の%値が当該の集団の全体にしめる比率となっている。
そして各ボックスから枝分かれする分岐にかかれている不等式が、ハイトランジションであることのリターンの分水嶺となる変数&分割条件となる。
上図の一番上の分岐までを例にすれば、ハイトランジションな試合における得点数の集団全体(100%)への影響は-0.0592点であるが、ボール支配率が59.8%以下の場合(86.3%)は-0.144点の影響であり、支配率が59.8%以上の層(13.7%)では平均的にハイトランジションな試合では得点が+0.487点アップする、という風に読んでいけばいい。
ということで、上図から読み取れるような以下のようなことだ。
- まず、トランジションの激しい展開であることが、ボール支配率を高めることの利得を高める。一番はじめの分岐にある通り、ボールを支配できるならハイトランジション化することは平均期待得点にプラスの効果をもつが、そうでない場合はむしろ下がる。すなわち、ハイトランジション化はボールを持てるチームが行ってこそ有効に機能する
- ポゼッションの高いチームのなかでは、対ロングボール阻止率が低いチームや、より多くのパスをつなげるチームが、ハイトランジション化の恩恵をより受けている。
ひとことで言えば、ハイトランジションな展開は、(ボールを持たせることよりも)自分達でボールを持ち、回すことに長けているチームの得点力により利する、ということが分かったと思う。
次は、失点数に関して、ハイトランジションな展開と交互作用がある変数をみつけよう。

ここから、以下のようなことが読み取れる
- 先ほどの得点に関する分析結果の裏返しとして、ハイトランジション化した試合では、最低限(4割以上)ボール持てないと期待される失点数が大きく増える。ゆえに、ボールを最低限保持する術のないチームが速い展開を志向するのは得策ではない。
- 最低限ボールを持てている場合、高いパス成功率とスプリント数の多さを両立できているなら、ハイトランジション化により大きく(一試合あたり約-0.5点ほど)期待失点数を下げることができる。
- トランジションの激しい展開とはすなわち、敵味方が近い位置で相乱れた状況が多く起きているということでもあるが、そういった状況ではスプリント能力による即時的なプレス試行や、逆に正確なパス回しによるプレス回避の利得が高まる、ということではないだろうか。
つまり、簡単にいえば、ボールが最低限持てて、パスがうまくて走れる(長い距離というよりは瞬発力を何度も発動させられる、的な意味で)チームであれば、ハイトランジションな展開にすることでより失点を抑えられるということである。
総じて分析を通じてわかったのは、「トランジションの激しい展開を志向する場合、"ボールを持てる"チームでないと攻守両面で大きなリターンは得られない」ということである。
攻守が苛烈に入れ替わる激しい展開に持ち込むことは、ボール保持が苦手なクラブにとっての「逆襲の一手」にはならず、むしろボール保持が得意なクラブがそこからくる優位性をさらに拡大するために利用されるものである、ということである。
この条件にもっとも合致し、ハイトランジション化による利益を最も享受しているチームは、(おそらくここまで読み進めている人ならだいたい頭に浮かんでいるだろうが)近年のJリーグでは横浜F・マリノスだといえる。
彼らは高いボール保持率・パス成功率を維持するだけでなく、この3年でのスプリント数も常にTop3(2020年2位、2021年1位、2022年暫定3位)にランクインしている。
おまけ:マイクラブ(名古屋)についての考察
完全に趣味でやっている分析なので、何の脈絡もなく急に、私の応援しているクラブである名古屋グランパスについて考える。
マッシモ・フィッカデンティから長谷川健太に監督が代わり、志向するサッカーがよりハイトランジションな方向性になっていることは、多くの人が感じているだろう。
「ファストブレイク」という言葉*5や就任以来の会見コメントを読んでいる限り、
- ボールを奪われても自陣に下がりすぎず、チームの重心をそこまで下げない状態での再奪回をめざす
- チームの重心がある程度高い状態でのボール奪取ができたら、そのままの勢いで速く&早く攻める
というのが長谷川名古屋のめざすサッカーのひとつの理想像であること自体は、疑いがないように思える。
実際にプレス試行率・成功率の去年/今年の対比図(再掲下図)を見ても、去年に比べプレス試行率はぐっと上がっている(成功率はあまりかわらないけど)。

ただ、この記事でここまでの分析結果(=「トランジションの激しい展開を志向する場合、"ボールを持てる"チームでないと攻守両面で大きなリターンは得られない」)をふまえると、「速い展開」からうまくリターンを得るには「ボールを正確につなぐ力」が必要であり、現状の名古屋はそこに不安要素があるというのが個人的な見方である。
これは長谷川さんがどうというよりも、前体制から変わらない課題(もっといえばトメルケルを重視していた前々体制でも十分にできていたかというと怪しい*6)であって、自陣深くに押し込まれたところから「ボールを持ちながら」陣地挽回をしていく、ことは近年の名古屋はずっと不得手としてきたと思う。
これは誰か特定の監督が(=長谷川さんが...、マッシモさんが...、風間さんが...)「悪い」という話ではなく、単純にクラブとしてそこに長期的な優位性をつくる努力をあまりしてこなかったという話であって、だから「失点期待値を極限までゼロに漸近させることで、ボールを保持し、運び、崩すことに関する諸問題は一旦棚上げしても結果を残す」というマッシモ・フィッカデンティの方向性は少なくとも短期的視野では間違いではなかったと思う。
(岡田武史さんがインタビューで言ってたけど、Jリーグの監督は基本的にmanagerではなくhead coachなので、自分の在任期間を超えた長期的リターンを向上させるインセンティブはない)
ただ(恐らくお金の問題とか)色々あってマッシモ体制のチームを引き継ぐことになった長谷川体制が、どういった方向性で前体制からの「差別化」をはかるのかという問題に対し、より「速いサッカー」の実現が打ち出しているのは、皮肉にも前々体制で目指さ(れそして達成できなかっ)た「ボールを正確に保持しながら前に進むこと」との再びの格闘を余儀なくされる道でもある、というのが本記事の分析からの示唆である。
いってみれば、「各個人が全員めっちゃうまくなって、完璧にボール扱って支配し続ければ守備考えなくてもよくね?」という愛すべき変態マッドサイエンティスト頑固親父風間八宏から、
「クソ強くて走り回れる個で守備ブロック作って90分守り切れば、ラッキーでも何でも1点とれば勝てるくね?」という180度方向性が反対の愛すべき頑固親父マッシモ・フィッカデンティに舵を切るという、
アクロバティックな頑固親父*7リレーを実行し、11年ぶりのタイトルにこぎつけたのがJ2降格以降の我がグランパスの歩みであった。
このアクロバティック頑固親父リレーの次を担うことになった、「3人目の親父」(なんか生活指導担当も兼務している学年主任の先生みたいな感じを醸し出している)こと長谷川さんは、重心低めだった2人目の親父からの差別化としてよりアグレッシブでハイトランジションな方向性をめざしつつ、そこで結果を出すために1人目の親父がやり残した"ボールをつなぎ、動かす"ことのアップグレードにも取り組まなくてはならない、ということである。
ここまで来てみると、36歳と決して若くないレオ・シルバが現状基本外せなくて、なんとかずっと持たせたいと考えている(徳島戦前会見参照)のも、なんとなくわかるというか。。
こう書くと、なんか今シーズンの名古屋ってすごい大変そうじゃないか?AFCが仕事しないせいでクバが半年音沙汰すらなく放置されてるしって思えてしまうけど、別に不安を煽るつもりはなくて、そういう難しい課題に取り組む時期だからこそチャンスを得られる選手もいるだろうし、色んな試行錯誤・七転八倒・右往左往を楽しむってことがフットボールを愛するってことなんじゃ?っていう心持ちで応援していきたいな、と思っております。
感想・雑感
たくさんのクラブがありたくさんの監督がいるこのスポーツで、記者が「理想とするサッカー」を訊き、それに監督が回答するという場面は何千回・何万回と繰り返されてきていて、そこで「"速い"サッカー」というワードが出てくることは珍しくない。実際にJもハイトランジション化の傾向がみられ、ハイトランジションな展開を得意とするチームが勝ち点を得ている。
でも前提として、あなたのクラブがそもそもボールを持てないんだったら、展開を速くしてもそこから得られる果実は少ないよ、というのが今回の学びであった。
ボールをうまく扱える仕組みや選手を揃えている強者の強みをむしろ拡大するのがハイトランジション化で、それを世界最高レベルで遂行しているのがリバプールなんだろうな、とも思ったり。
名古屋に関しては、アカデミー育ちの選手(藤井陽也とか吉田温紀とか宇水とか、今はレンタルされてるけど成瀬とか)がそこらへんで起爆剤になったりしたらいいな、と夢想したり。
かなり前に書いた記事(一般ファン・サポーターがJリーグを統計的に楽しむうえで「できないこと」は何か - 論理の流刑地)でも書いたのだけど、もっとちゃんとメカニズムを明らかにしたり因果関係に言及したりしたいのであれば、時間や空間の情報を入れたメトリクス(プレス後N秒以内の奪回率とか、ボール奪回後N秒後の平均的な前進距離とか)を分析に組みこむ必要があるんだと思うんだけど、それは今利用可能なデータの粒度じゃ難しいので、今後の課題としたい。
Enjoy!!
*1:攻撃回数って、タッチやサイドライン割ってCKやこっちのスローインで始まっても加算されちゃうんで、そっちのほうがいいのかなと思ったのですね
*2:ただ、この「攻撃回数」をもとにしたトランジションの指標化は、実際にトランジションをカウントして得られた数値からはやや大きめに出る(Tanalifeさんのtweet参照)も頭に入れといた方がよい
*3:メインの分析では、トランジション数上位1/3=1,それ以外=0の値をとる二値変数としている
*4:今年に関してはまだ4割くらいしか消化していないので参考程度だが
*5:最近はあまり会見でも口にしていないが
*6:押し込んでいる展開では確かに技術が活きていたと思うけど、それはかなり属人的であって、後ろからどう再現性のある形でボール保持しつつチーム全体を押し上げるのか、という問いに風間さんは答えを持っていなかったと思う。それはある意味確信犯的な「属人性」の重視でもあったと思うのだが
*7:これ自体は褒め言葉です。とりあえず関わってくれた監督は全員愛することにしているゆえ。でも強化部はもうちょっと「グランパスはこういうサッカーをめざす」ってのを言語化したほうがいいと思うけど..
【R】{randomForestSRC}パッケージの基本事項備忘用メモ
なんか日本語情報が全然なかったので、自分用メモ
別にrandom forestの計算ロジック自体が変わるわけではないので*1、情報がなくても不思議じゃないんだけど。
ちょいちょい触ってみて、{randomForest}パッケージより使いやすいと思ったので必要最小限に書き残す
参考URLなど
基本的には公式チートシートみればよくて、それが分からなかった関数一覧のページ見ればだいたい事足りる(んだけど一応自分用にメモする)
普通に使う
とりあえず著名なデータセットであるボストン住宅価格データとアヤメ(iris)データ*3を使う
data(Boston , package = "MASS") data( iris)
実行のコードはあまり{randomForest}とかわらない。
だいたい引数でいじるのは、ntree(生成する木の数), mtry(選ぶ変数の数。回帰問題ならデフォ値でそれ以外はデフォ値
), nodesize(ノードに含まれるべき最小ケース数)あたりくらい。
分類問題
rf_cls0 <- rfsrc( Species~ . , data = iris , nodesize = 4 ) print( rf_cls0 )
(summary()ではなく)print()したときに割といい感じの欲しい情報をまとめて出してくれるので、おぼえとくとよい

回帰問題
rf_reg0 <- rfsrc( medv ~ . , data = Boston, nodesize =5 ) print( rf_reg0)

生存問題
(いつかつかうときが来たらここに追記する)
パラメータチューニング
randomForestSRC::tune()を使うと、mtryとntreeに関して最適な値をみつけてきてくれる
## 回帰問題 ## # mtryとnodesizeについて最適化 ptune_reg0 <- randomForestSRC::tune( medv~. , data = Boston) # nodesizeを固定にする ptune_reg0_2 <- randomForestSRC::tune( medv~. , data = Boston,nodesizeTry = 5) #結果 ptune_reg0$optimal # nodesize mtry # 1 13 ## 分類問題 ## ptune_cls0 <- randomForestSRC::tune( Species~.,data =iris) #結果 ptune_cls0$optimal # nodesize mtry # 3 3
分析後の可視化いろいろ
予測精度を評価する
MSEとか一致率を求める
$predictedでIn-Bagに対する予測値を、$predicted.oob はOut-Of-Bagに対する予測値を取り出せる
ただ計算するだけなのもアレなので、伝統的手法とくらべてみる
library( tidyverse) ##分類:Multinomial Logitと比較 library(mlogit) iris_md <- mlogit.data( shape = "wide" , data = iris , choice = "Species" ) iris_ml0 <- mlogit( Species~ 0 | Sepal.Length + Sepal.Width+ Petal.Length+ Petal.Width ,data= iris_md) pred_lbl_ml <- iris_ml0$probabilities %>% apply( 1 , function(x){ return( which( x == max(x))) }) %>% unlist pred_lbl <- rf_cls0$predicted.oob %>% apply( 1 , function(x){ return( which( x == max(x))) }) %>% unlist err_rate_ml <- 1 - ((as.numeric( iris$Species) ==pred_lbl_ml ) %>% mean) # 0.01333333 (Error rate) err_rate_rf <- 1 - ((as.numeric( iris$Species) ==pred_lbl ) %>% mean) #0.04 ( Error rate) ##回帰:普通にOLSする場合との比較 ols0_bos <- lm( medv~ . , data = Boston) # R^2 = 0.7406 mse_ols0 <- mean( (Boston$medv- ols0_bos$fitted.values ) **2) #21.89483(MSE) mse_rf0 <- mean( (Boston$medv - rf_reg0$predicted.oob) **2) #11.22804(MSE)
まぁ、造作もないですが。
なんかirisデータの分類に関しては普通に多項ロジットやったほうが正確だ....
変数重要度
○回帰問題
vimp_reg0 <- vimp(rf_reg0) plot( vimp_reg0)

おなじみの図
○分類問題
vimp_cls0 <- vimp( rf_cls0) plot( vimp_cls0) vimp_cls0$importance #重要度一覧

おなじみの図,part2
Partial Dependence Plot
各変数に対するpartial dependence plot(わかりやすい解説は「変数重要度とPartial Dependence Plotで機械学習モデルを解釈する - Dropout」とか参照)は、plot.variable()で引数partial=Tを指定することで得られる
plot.variable( rf_reg0,partial = T) #回帰 plot.variable( rf_cls0,partial = T) #分類

交互作用をみつける
結構便利な機能。アウトカムYに対して、変数の中から交互作用の大きい組み合わせをみつける手助けをする
method引数に"vimp"(変数重要度の増減への寄与基準)か”maxsubtree"(分割に各変数が現れる深さ基準)かを選べる。
vimpのほうが直感的で好みである。その説明(URL)をみよう
method="vimp" This invokes a joint-VIMP approach. Two variables are paired and their paired VIMP calculated (refered to as 'Paired' importance). The VIMP for each separate variable is also calculated. The sum of these two values is refered to as 'Additive' importance. A large positive or negative difference between 'Paired' and 'Additive' indicates an association worth pursuing if the univariate VIMP for each of the paired-variables is reasonably large. See Ishwaran (2007) for more details.
とある。まぁ詳細は元論文をよまないと分からんけど、
二変数の組み合わせから算出できる"paired importance"と単なる二変数のimportanceの和(="additive" importance)の値を比べて、そこに差があってなおかつ元の各変数のimportanceも高ければ、そこには分析しがいのある交互作用があるよ、ということらしい。
※プラスはなんとなくわかるけど、マイナスってどういうこと?ってのがよくわからない。。
※paired importance基本的に総当たりで計算しているので、変数の数が多すぎるときは引数nvarで絞ると良い
とりあえずやってみる
### 交互作用をみつける ### int_reg0_1 <- find.interaction(rf_reg0,method= "vimp") int_reg0_1 %>% head()
以下のようなデータフレームがアウトプットとなっている

Differenceの絶対値でソートして、top5をみてみる
dfInt_reg0 <- int_reg0_1 %>% as.data.frame() %>% mutate( abs_diff = abs(Difference)) %>% arrange( desc( abs_diff)) head( dfInt_reg0,5)

difference上位の交互作用項がほんとに有意を、OLSであらためてたしかめてみる
ols1_bos <- lm( medv ~. + lstat:rm + rm:ptratio, data = Boston) summary( ols1_bos)

OLSでも交互作用項が有意になっていることが確認できる
感想
わりと使いやすそうだし、何よりわかりやすめなので、今後random forestを使うときは{randomForestSRC}も良い選択肢だな、と思いました。
PDPの図示とか交互作用の探索とかもパッとできるので、プレ分析用のツールとしてはよい気がする
Enjoy!!
【R】ありがたき{crosstable}パッケージで、集計や基礎分布の確認をラクにする
Introduction
高度*1な手法を使って効果検証や仮説探索を行う前に、まずどういうデータなのか確認するために2~3変数の関連をクロス表などで確認したい、ということは多い。
そういったときに、使えるのが最近開発された{crosstable}である。
"習うより慣れよ"なので、自分でコードを書きながら、主要な使い方のメモをここに残す
◆参考URL
引数の説明
公式ページの冒頭に
Crosstable is a package centered on a single function, crosstable, which easily computes descriptive statistics on datasets.
とあるように、基本的に{crosstable}パッケージはcrosstable()関数を理解すれば必要十分であるようになっている。
※一応Excelとの連携用の関数とかも充実しているっぽいが、ここでは触れない
ということで、主要な引数をみていく
- data: 第一引数, 対象のデータフレーム
- cols: 集計対象とする変数の指定ベクトル, NSEっぽく指定してもいいし(例 cols = c(var1, var2))、そのまま文字列で指定(例:cols=c("var2”, "var3"))してもいい。あとはtidyselectな感じでstart_with()とかcontains()とかも使える。詳しくはSelect variables • crosstableを参照のこと。
- by:グループ変数の指定。単一の変数でも、複数の変数でもよい(NSE指定 or 文字列指定)。基本的にはカテゴリ変数を指定する(byにnumeric変数を指定すると、相関が計算される)
- total:周辺度数をあらわすセルを追加するかどうかの指定。デフォルトは"none"(表示しない)で、"column"(列だけ追加),"row"(行だけ)、"both"(両方追加)のオプションがある
- percent_pattern:カテゴリ変数の場合に意味を持ってくる引数で、度数およびパーセントの表示形式を指定する{n}は度数,{p_col}, {p_row}はそれぞれ列/行%である。percent_pattern= "{n}({p_col})"のような形で、度数とパーセントの表示の仕方を指定する
- num_digits, percent_digits, 各セルの数値、パーセントに対する表示桁の指定
- labels:TRUE or FALSEを指定。TRUEのときはラベルを使う。ラベルはset_labels()を使って、mutate(new_col = set_labels(col, "This is Label."))のように設定する
- funs:数値変数に適用する関数をc(..)で指定する(何も指定しないとMin/Max, 中央値/IQR, 平均[標準偏差]が出力される)。
- funs_arg:funsに指定した関数の追加引数をlist形式で指定する。(例: crosstable(..., funs = c(quantile), funs_arg = list( probs= c(0.25 ,0.75)) )
- cor_method:byにnumeric変数を指定すると相関が計算されるが、相関の計算方法を指定("pearson" or "spearman" or "kendall")
- showNA:グループ変数がカテゴリである場合、NAの水準も表示するかどうか。"none"(デフォルト)、"ifany"、"always"のどれかを指定
だいたい上記が基本的によく使う引数っぽい。
よくある使い方の例
代表的な使い方についてコードをみていく
as_flextable()関数を使うことで, RStudioのViewerにHTML-likeな感じで表示できる、ので以下コードでもそうしている。
いつものように、{panelr}の賃金データを例につかう
data(WageData) dWage <- WageData %>% mutate( sex = if_else( fem == 1 , "female","male"), #性別 ed2 = if_else( ed > 12 , "high","low"), #学歴 occ2 = if_else( occ == 1 , "WC","BC")) #職業
数値変数の基本統計量
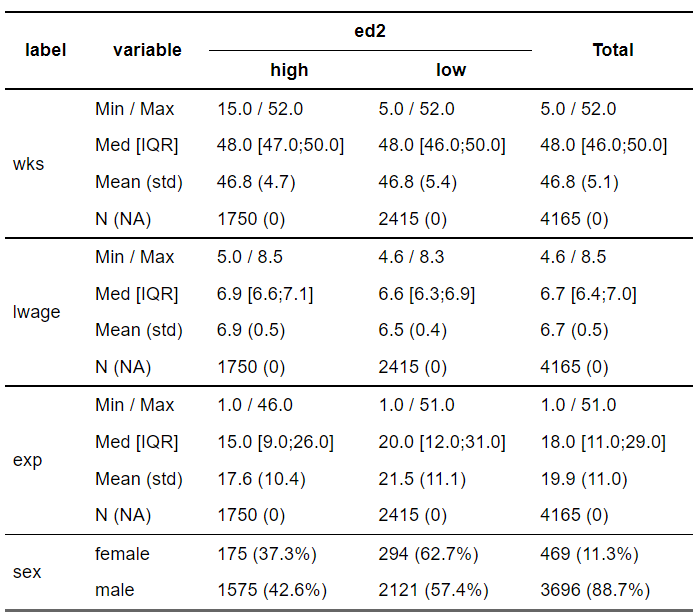
まず、基本的な使い方として、.funsに何も設定せずに、colsにnumericの変数を設定すると、最大値/最小値, 中央値/IQR、平均値/標準偏差, Nをグループ変数の値に応じて出力してくれる
dWage %>% crosstable( cols = c(wks , lwage , exp), by = c(ed2),label=F) %>% as_flextable(keep_id= F)

カテゴリ変数の要約&列和を表示する
カテゴリ変数に関しては、分布が示される。また、行の周辺度数をみたいので、total="row"をたしてみる。
dWage %>% crosstable( cols = c(wks , lwage , exp,sex), by = c(ed2), percent_digits = 1, label=F, total = "row") %>% as_flextable(keep_id= F)
要約統計量の関数を自分で指定する
各変数ごとに確認したいのが分位点の場合、以下のようにfuns, funs_arg関数を使って指定する
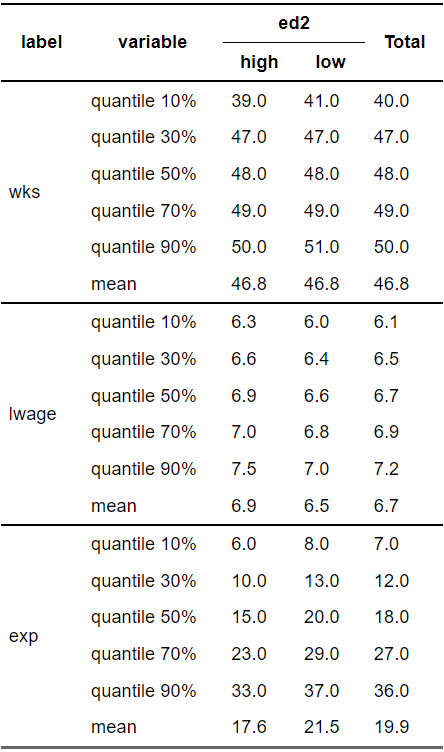
下の例だと、平均も求めている
dWage %>% crosstable( cols = c(wks , lwage ,exp), by = c(ed2), label=F, funs = c(quantile,mean), funs_arg= list( probs = seq( 0.1 , 0.9 , by = 0.2)), total= "row") %>% as_flextable(keep_id= F)
グループ変数をふたつにする
個人的にこれが一番便利なんちゃうかな、という使い方
たとえば、学歴× 職業別に賃金,経験年数, 労働時間の分位点をみたいときなんかは以下のようにする
## 二変数で層別 dWage %>% crosstable( cols = c(wks , lwage , exp ), by = c( ed2 , occ2 ), total = "row", label=F, funs = c(quantile , mean), funs_arg= list( probs = seq( 0.1 , 0.9 , by = 0.2)) ) %>% as_flextable( header_show_n =T)

特殊な使い方
advancedな機能として、いくつか特定の用途に特化したオプションがあるので、そちらも見てくる
相関係数の表示
グループ変数を離散変数から連続量(教育年数)にかえて、相関関数を求める
dWage %>% crosstable( cols = c( wks , lwage, exp ), by = c(ed), label =F ,cor_method = "pearson", total="row" ) %>% as_flextable()

効果推定
effect=TRUEにすると、変数のclassに応じて、効果推定をしてくれる(byに指定されているのが二水準の変数ひとつの場合のみ)
詳しい指定の仕方とかは、Default arguments for calculating and displaying effects in crosstable() — crosstable_effect_args • crosstable(とそこから飛べる各関数のページ)を参照のこと
dWage %>% crosstable( cols = c(wks , lwage , exp), by = c(ed2), percent_digits = 1,funs = mean , label=F, total = "row" ,effect = T) %>% as_flextable()

連続量の場合は、内部で分布の正規性の判定がされて、正規分布だとみなされるならt検定が、そうでないのならbootstrap法での検定がなされるみたいだ。
おおまかな使いかたはわかった。
ひとまず初顔合わせのデータと仲良くなりたいときとかには使えるだろう
Enjoy!!
*1:というほど高度でもないことも多いが